DeepSeek-OCR : quand l’IA apprend à *voir* le texte autrement

« Et si la prochaine révolution de l’intelligence artificielle ne venait pas des mots, mais des images ? »
C’est la question que je me suis posée en découvrant DeepSeek-OCR, le nouveau modèle open-source publié par DeepSeek AI. Derrière ce nom sobre se cache une innovation discrète, mais radicale : un modèle d’OCR capable non seulement de lire les documents, mais surtout de compresser le contexte visuel d’un texte entier pour le rendre exploitable par un modèle de langage. Autrement dit : une façon de voir et comprendre le texte, plutôt que de le découper.
Les références de cet article sont tirées de l'abstract officiel de Deepseek.
Une nouvelle génération d’OCR
Pendant longtemps, l’OCR (Optical Character Recognition) s’est résumé à une promesse simple : extraire du texte à partir d’une image ou d’un PDF. C’était pratique pour numériser des archives ou lire un reçu, mais limité dès qu’il s’agissait de comprendre un document complexe — tableaux, schémas, rapports de plusieurs centaines de pages.
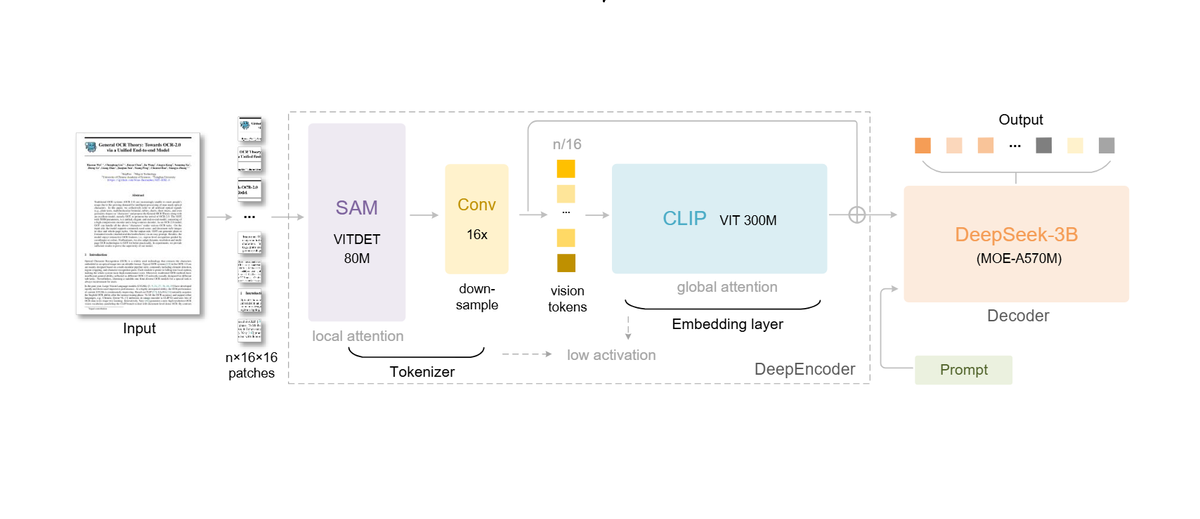
DeepSeek-OCR change la donne. Il repose sur un double mécanisme :
- un encodeur visuel (DeepEncoder) qui transforme les pages en tokens visuels ;
- un décodeur linguistique (DeepSeek-3B-MoE-A570M) qui lit ces tokens pour restituer le texte.
La prouesse réside dans la compression du contexte. Le modèle peut réduire un document jusqu’à 10 fois tout en conservant près de 97 % de fidélité. Concrètement, là où un modèle classique doit traiter des milliers de tokens pour comprendre un dossier, DeepSeek-OCR en traite dix fois moins, sans perdre le sens global.
« Nous voulons rendre lisible l’invisible », expliquent les chercheurs de DeepSeek.
C’est exactement ce qu’ils font : transformer la structure visuelle du texte en un format que l’IA peut ingérer plus efficacement.
Pourquoi c’est une révolution discrète mais majeure
Le sujet peut sembler technique, mais l’impact est immense. Jusqu’ici, les grands modèles de langage (GPT, Claude, Gemini…) étaient limités par leur fenêtre de contexte — la quantité de texte qu’ils peuvent “retenir” à la fois. Même avec 200 000 tokens, il faut encore découper, segmenter, indexer. Ce qu’on appelle communément un pipeline RAG (Retrieval-Augmented Generation).
Le problème : chaque fois qu’on fragmente le texte, on perd une partie de sa cohérence narrative. Les références croisées, les dépendances entre paragraphes, les schémas logiques se dissolvent.
Avec DeepSeek-OCR, le paradigme change. Au lieu de découper un rapport en petits morceaux, on le compresse dans sa globalité — comme une image mentale que le modèle garde en mémoire. Cela ouvre la voie à une nouvelle forme de contexte long, où la machine n’a plus besoin de scinder pour comprendre.
Imaginez pouvoir faire lire à une IA un rapport annuel de 500 pages, ses annexes et graphiques inclus, sans perdre le fil. C’est exactement la promesse ici : moins de tokens, plus de contexte.
Des perspectives concrètes (et crédibles)
Plutôt que d’énumérer des cas d’usage sectoriels, je préfère partager ce que cela change dans la pratique.
Aujourd’hui, tout professionnel manipulant des documents volumineux se heurte au même mur :
- le coût de traitement explose avec la taille du texte ;
- la segmentation du contenu réduit la précision ;
- les formats mixtes (texte + visuel) restent difficilement exploitables.
DeepSeek-OCR, par sa nature hybride, réconcilie ces mondes. Un contrat scanné n’est plus seulement une suite de caractères : c’est une carte visuelle où le modèle comprend la structure, les tableaux, les titres, les marges. Un rapport PDF n’est plus un fichier inerte : c’est une image de pensée que l’IA peut résumer ou questionner sans perdre le sens global.
C’est un peu comme si on passait d’une lecture mot par mot à une lecture photographique.
Dans un monde où la donnée explose, cette capacité à ingérer sans morceler peut redéfinir la manière dont on construit des systèmes d’analyse, de veille, ou même de mémoire d’entreprise.
Sous le capot : la « compression visuelle »
Pour vulgariser sans trahir : le modèle encode chaque page en carte visuelle compacte. Cette carte contient non seulement les caractères, mais aussi leur spatialisation (emplacement, hiérarchie, regroupements). L’ensemble est ensuite converti en vision tokens, beaucoup moins nombreux que des tokens textuels classiques.
Résultat :
- un gain d’efficacité spectaculaire ;
- une réduction du coût d’inférence ;
- et surtout, une conservation du contexte spatial qu’un LLM standard perd complètement.
Autrement dit, l’IA ne lit plus un texte comme une suite de mots, mais comme un espace sémantique. Et c’est peut-être cela, la vraie rupture.
Un potentiel à manier avec réalisme
Toute révolution technique a ses angles morts. DeepSeek-OCR n’échappe pas à la règle. La précision chute au-delà d’un certain taux de compression (environ 60 % à 20×). Et pour l’instant, les performances observées restent issues d’environnements contrôlés.
Mais même en l’état, le signal est fort. L’open-source permet déjà d’expérimenter, d’intégrer le modèle dans un pipeline RAG existant, ou même d’envisager des pré-traitements visuels avant génération de texte.
Ce n’est donc pas un remplacement des modèles existants, mais un complément radicalement nouveau. L’OCR devient une passerelle entre le document et la compréhension contextuelle.
En conclusion
Je crois que DeepSeek-OCR ouvre une brèche dans le mur actuel du contexte. Nous sommes peut-être en train d’assister à la naissance d’une génération d’IA capable non seulement de lire plus vite, mais surtout de comprendre à travers la forme.
Dans un monde saturé de texte, c’est une évolution précieuse. Et si demain, nos modèles de langage pensaient en images ?
DeepSeek-OCR vient peut-être d’apprendre à l’IA à regarder autrement.