Héberger son modèle de transcription

Si vous souhaitez rester maître de vos données et vous affranchir des API OpenAI pour la transcription des messages vocaux de vos agents IA, cet article est pour vous.
Il existe plusieurs modèles dit Speech-To-Text, le plus simple est de commencer par connaître la capacité du serveur sur lequel on souhaite installer le modèle.
Dans mon cas, je pars sur un serveur CPU kvm2 de Hostinger. Le modèle le plus intéressant reste faster-whisper qui est basé sur le modele open source d'open AI whisper.
faster-whisper - a Systran Collection
faster-whisper is a reimplementation of OpenAI’s Whisper model using CTranslate2, which is a fast inference engine for Transformer models.

Ci-dessous le docker-compose pour la déclinaison 'base' pour l'installation.
faster-whisper-cpu:
image: "onerahmet/openai-whisper-asr-webservice:latest"
container_name: faster-whisper-cpu
restart: unless-stopped
ports:
- "9000:9000"
environment:
- ASR_MODEL=Systran/faster-whisper-base
- ASR_ENGINE=faster_whisper
- LANGUAGE=fr
command: >
--model Systran/faster-whisper-base
--language fr
--device cpu
--compute_type int8Une fois que l'installation est terminé. Redémarrez votre conteneur avec
docker compose down && docker compose up -dIl vous permet d’envoyer directement un fichier audio via une simple requête HTTP et de récupérer la transcription en retour.
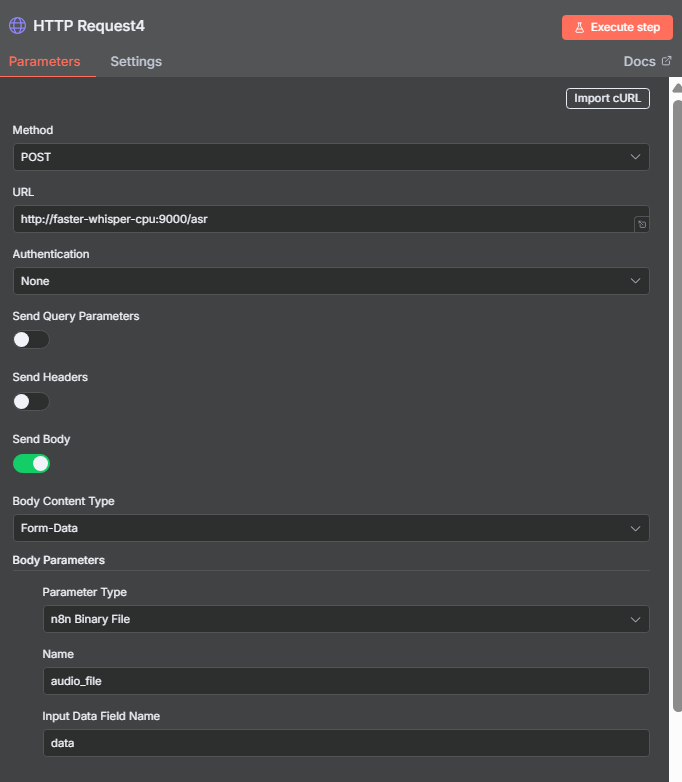
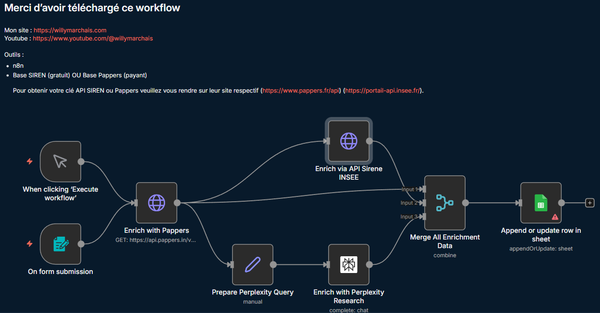
Vous pouvez d’ailleurs encapsuler ce nœud dans un sous-workflow réutilisable par tous vos agents : WhatsApp, Frontend, ou tout autre canal.