🟡Lakehouse (ou comment visualiser 10 milliards de données)
Du CSV brut au Dashboard Power BI – Guide complet pour une mise en production industrialisée

Du CSV brut au Dashboard Power BI – Guide complet pour une mise en production industrialisée
Une architecture pensée pour l’évolutivité, la qualité des données et l’exploitation temps-réel
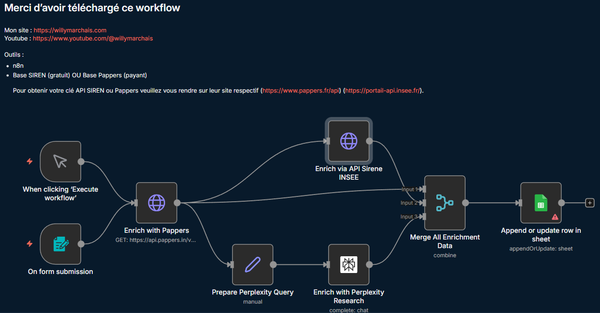
Dans cet article, je souhaite vous partager pourquoi une architecture Lakehouse Fabric en trois temps (Bronze → Silver → Gold) est, selon moi, le meilleur compromis entre agilité et gouvernance pour transformer n’importe quel fichier CSV en table de bord Power BI en production – et ce, sans copier vos données ni sacrifier la traçabilité. Après avoir accompagné plusieurs équipes sur des plateformes de plusieurs péta-octets, j’ai vu trop de projets échouer faute d’un socle clair : ingestion brute, transformations réversibles et exposition instantanée. Ce guide condense l’approche que j’utilise aujourd’hui : un Copy Job sans transformation pour le médaillon Bronze, un notebook PySpark réutilisable pour la Silver, et un modèle étoile Delta accessible en temps réel via DirectLake. Si vous cherchez à industrialiser vos données tout en gardant la main sur la qualité, ce récit est pour vous.
Qui suis-je ? Architecte, ingénieur, CTO, j'accompagne les entreprises à mettre en production des systèmes Data & IA à grande échelle.

📍 Contexte du projet
Dans le cadre de la modernisation d'une plateforme client, j'ai conçu et intégrer une architecture Fabric Lakehouse suivant les principes medallion (Bronze → Silver → Gold). Cette architecture permet d’industrialiser le traitement des données tout en garantissant traçabilité, qualité et performance.
📂 Arborescence complète du projet
🧱 Workspace Fabric : ws-prod
ws-prod/
├── Lakehouses/
│ └── lh-prod/
│ ├── Files/
│ │ ├── 1-BRNZ/ ← Bronze : données brutes
│ │ │ ├── public.product/
│ │ │ │ ├── _delta_log/
│ │ │ │ └── part-*.parquet
│ │ │ └── public.customer/
│ │ ├── 2-SLV/ ← Silver : données nettoyées
│ │ │ ├── product_clean/
│ │ │ └── customer_clean/
│ │ └── 3-GOLD/ ← Gold : modèle étoile
│ │ ├── fact_sales/
│ │ ├── dim_product/
│ │ ├── dim_customer/
│ │ └── dim_date/
│ ├── Tables/ ← Tables enregistrées
│ └── SQL Analytics Endpoint/ ← Connexion BI
├── Notebooks/
│ ├── nb_bronze_to_silver.py ← Transformation Silver
│ ├── nb_silver_to_gold.py ← Modélisation Gold
│ └── nb_data_quality.py ← Tests qualité
├── Pipelines/
│ ├── pl_bronze_ingestion ← Copy Job → Bronze
│ ├── pl_silver_transformation ← Bronze → Silver
│ └── pl_gold_modelisation ← Silver → Gold
├── Data Factory/
│ └── Copy Jobs/
│ └── cj_vehicle_csv_to_delta ← Ingestion sans transformation
└── Power BI/
└── Sales Dashboard.pbix ← Dataset DirectLake
Flux de données détaillé
Phase 1 : Ingestion Bronze (Zero-ETL)
Objectif : Capturer les données sources sans transformation pour garantir une archive fidèle, profiter des copy jobs et éviter les charges.
Configuration du Copy Job
{
"source": {
"type": "DelimitedText",
"fileName": "public.vehicle.csv",
"location": "ADLS Gen2"
},
"destination": {
"type": "Lakehouse",
"folderPath": "Files/1-BRNZ/product.vehicle",
"format": "delta",
"writeMode": "overwrite"
},
"settings": {
"firstRowAsHeader": true,
"compression": "snappy"
}
}
Avantages de cette approche
- Traçabilité complète : conservation de l'intégralité des données sources
- Rejeu possible : en cas d'erreur de transformation, on peut retraiter depuis Bronze
- Auditabilité : conformité réglementaire (RGPD, SOX...)
Phase 2 : Transformation Silver (Notebook PySpark)
Objectif : Nettoyer, standardiser et enrichir les données.
Notebook nb_bronze_to_silver.py
# Lecture Bronze
df_bronze = spark.read.format("delta").load("Files/1-BRNZ/public.product")
# Transformation Silver
df_silver = (df_bronze
.filter(col("product_id").isNotNull())
.withColumn("registration_date", to_date("registration_date", "yyyy-MM-dd"))
.withColumn("engine_power_kw", col("engine_power_hp") * 0.7457)
.dropDuplicates(["product_id"])
.withColumn("processed_at", current_timestamp())
)
# Écriture Silver avec partitionnement
df_silver.write \
.format("delta") \
.mode("overwrite") \
.option("mergeSchema", "true") \
.partitionBy("year", "month") \
.save("Files/2-SLV/product_clean")
Phase 3 : Modélisation Gold (Modèle étoile)
Objectif : Structurer les données pour l'analyse multidimensionnelle.
Notebook nb_silver_to_gold.py
# Tables dimension
dim_vehicle = df_silver.select(
"product_id", "brand", "model", "year", "engine_type"
).distinct()
dim_date = spark.sql("""
SELECT DISTINCT
registration_date as date_key,
year(registration_date) as year,
month(registration_date) as month,
dayofweek(registration_date) as weekday
FROM product_clean
""")
# Table de faits
fact_sales = df_silver.select(
"product_id",
"registration_date",
"sale_price",
"margin"
)
# Sauvegarde Gold avec optimisation BI
(fact_sales.write
.format("delta")
.mode("overwrite")
.option("delta.enableChangeDataFeed", "true")
.save("Files/3-GOLD/fact_sales"))
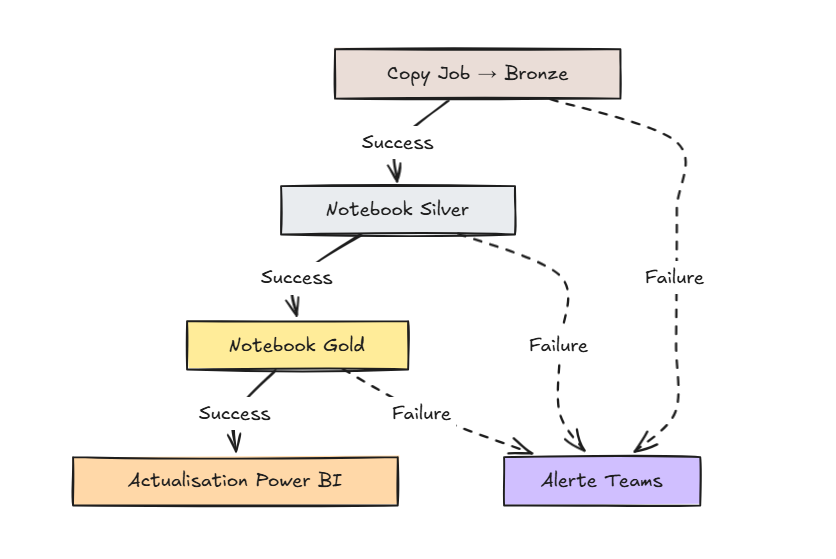
🎯 Orchestration via Pipeline
Pourquoi orchestrer ?
- Gestion des dépendances : Silver ne démarre que si Bronze est OK
- Déclencheurs Batch / Quotidien - Hebdos...
- Surveillance : alertes en cas d'échec
- Reprise sur erreur : retry automatique
- Audit temporel : logs détaillés
Pipeline pl_full_load
💎 Format Delta : Pourquoi c'est critique
Propriétés ACID garanties
| Propriété | Implémentation Delta | Bénéfice |
|---|---|---|
| Atomicity | Transaction log _delta_log |
Pas de données partielles |
| Consistency | Validation du schéma | Évite la corruption |
| Isolation | Optimistic concurrency | Traitements parallèles sûrs |
| Durability | Écriture sur storage persistant | Pas de perte de données |
Fonctionnalités avancées
Pour aller plus loin, certaines fonctionnalités exclusives aux formats ouverts (open formats) offrent des avantages significatifs. C’est notamment le cas de la fonctionnalité "Snapshot", qui permet de consulter une version antérieure d’une table à une date donnée. Cela peut s’avérer particulièrement utile pour les tables de faits (fact tables), où il est parfois nécessaire de reconstituer l’état des données à un moment précis du passé. Par exemple, afficher la table "Sales" telle qu’elle était le 18 juillet 2023 peut se faire simplement à l’aide d’une requête SELECT avec une clause WHERE appropriée.
# Time travel - rollback possible
df_20240101 = spark.read \
.option("timestampAsOf", "2024-01-01") \
.format("delta").load("Files/2-SLV/vehicle_clean")
# Streaming + batch unifié
df_stream = spark.readStream \
.format("delta") \
.load("Files/1-BRNZ/public.vehicle")
🚀 Exploitation des données
Accès multi-couches
| Couche | Accès | Usage |
|---|---|---|
| Bronze | Notebook, Audit | Traçabilité réglementaire |
| Silver | SQL Endpoint, BI | Analytics opérationnels |
| Gold | Power BI DirectLake | Dashboards temps réel |
Connexions disponibles
- SQL Analytics Endpoint :
ws-prod.sql.azuresynapse.net - Power BI : Mode DirectLake (pas de copie)
- DBeaver : JDBC Azure AD
- API REST : Automatisation des rapports
Monitoring & Qualité
Métriques clés
- Volume : lignes par médallion
- Qualité : % de nulls, doublons détectés
- Performance : temps de traitement par étape
Alertes configurées
- Échec pipeline → Teams
- Anomalie qualité → Email
- Latence > SLA → SMS
Conclusion
Cette architecture Fabric Lakehouse offre :
- Scalabilité : passage de Mo à Pb sans refactoring
- Fiabilité : garantie ACID via Delta
- Agilité : exploration SQL sans copie de données
- Gouvernance : traçabilité complète Bronze → Gold
Pour aller plus loin : ajout du streaming pour les données temps réel et CI/CD Git pour les notebooks.